I had setup an Amazon RDS MySQL instance with Multi-AZ option turned on. However, I couldn’t test if the Multi-AZ setup was working as expected. Thus, I prepared the test cases below to simulate a downtime and verify if the Failover worked and the servers switched places.
I am assuming you have already setup a Multi-AZ RDS instance for MySQL. If not, check out http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.MySQL.html
How will we test it?
- Identify the two servers that AWS allocates to us (Primary & Secondary)
- Start adding data/load test one of the servers and do a reboot of that server to simulate a downtime.
- Review if the switchover happened, and the data consistency.
Base Setup
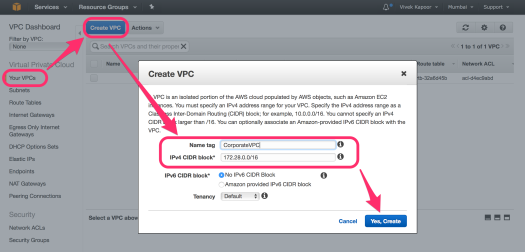
- Multi-AZ MySQL installation (db.t2.micro) in Mumbai Location (AP-South-1)
- Ubuntu EC2 Instance (t2.nano) in Mumbai Location (AP-South-1)
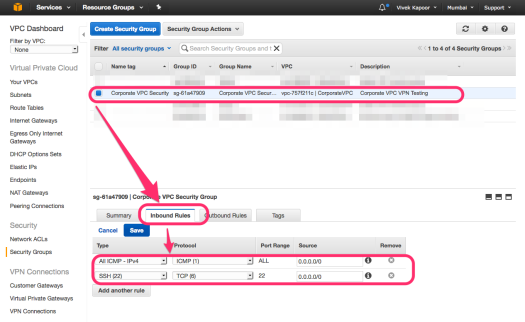
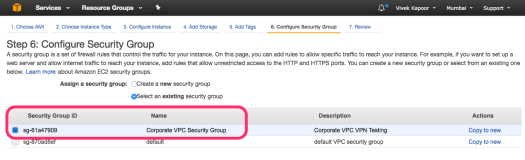
- Security Group Changes to allow access to the incoming port 3306 from the internal IP address of the EC2 instance.

Security Group Settings • 172.31.28.190 is the IP Address of the EC2 instance
Determine Primary & Secondary Zone IPs for your RDS instance
In Amazon RDS with a Multi-AZ setup, there are two availability zones within a location. Primary Availability Zone (referred as Availability Zone) & Secondary Availability Zone (Referred as Secondary Zone).
The purpose of Multi-AZ setup is that your database setup is running on an automatic failover environment with a realtime replicated standby server. In case the primary server goes down, the secondary server can elevate itself to primary and continue the services. Refer https://aws.amazon.com/rds/faqs/#129 and https://aws.amazon.com/rds/details/multi-az/
Endpoints & Availability Zones in RDS
Amazon RDS provides you with an Endpoint, which is a domain that you use as your hostname, and connect to your MySQL instance on Port 3306.
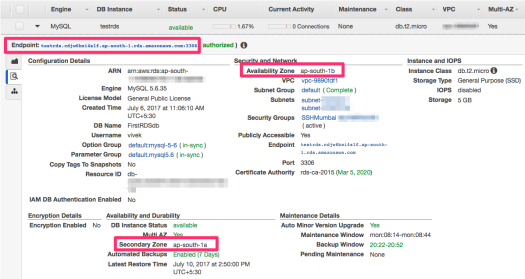
The Endpoint is a DNS CNAME that points at a time to one of the two instances available in the different availability zones (Primary & Secondary) with a TTL of 5 Seconds. The first step that we will follow would be to determine what are these two instances, and whether the availability zone has changed successfully.
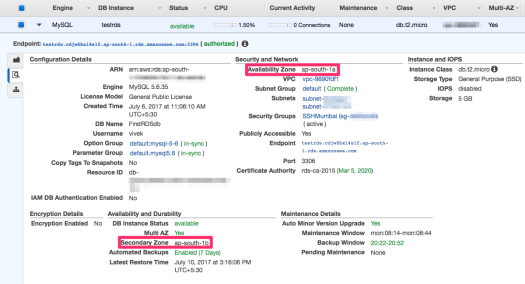
Note that the Availability Zone currently is ap-south-1b (as in the screenshot above), and the Secondary Zone is ap-south-1a.
For our reference, we’ll use testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com as the Endpoint that we have. Yours will of course vary.
On your EC2 terminal, run the following
while true; do host testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com | grep alias ; sleep 1; done
(you can exit using CTRL+C at any point of time)
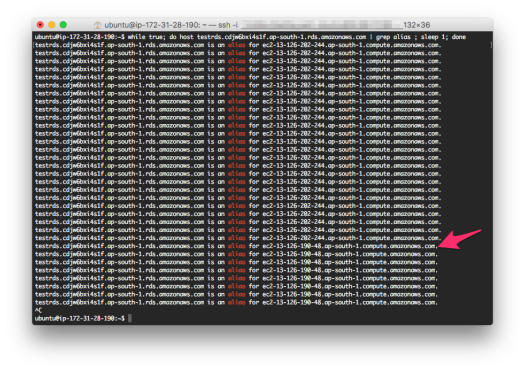
The above script will continue to check via DNS the pointer to testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com Endpoint. The result will be something like the following
testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com is an alias for ec2-13-126-202-244.ap-south-1.compute.amazonaws.com.
Note the alias name ec2-13-126-202-244.ap-south-1.compute.amazonaws.com.
It is the server that is running MySQL instance, and your scripts will connect to eventually. It is the MySQL server for ap-south-1b zone assigned to your instance.
Now let’s simulate a scenario through reboot where we will make the Secondary Zone the Primary.
- From your AWS console, select the DB Instance, and under Instance Options, select “Reboot”.
Rebooting RDS DB Instance
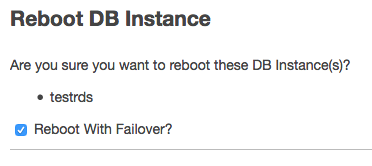
- Under the Reboot options, select the option “Reboot With Failover?”, and click Reboot.
Reboot With Failover option
- Continue to monitor the terminal where you were checking the domain name pointing for your Endpoint.
Endpoint’s DNS Alias Changes on Server Switching
It takes <60 seconds for the Endpoint DNS information to change. You will be able to see a new domain name that your endpoint is now pointing towards.
testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com is an alias for ec2-13-126-190-48.ap-south-1.compute.amazonaws.com.
You can refresh the AWS console. It takes within a few seconds to <10 minutes to see the updated Availability Zone information on the AWS console.
Availability Zone Switchover successful
If you notice, the Availability Zone has now become ap-south-1a (instead of 1b), and Secondary Zone is now ap-south-1b (instead of 1a). Hence the servers have interchanged, and now you can connect only to the Primary Server.
Results for the above setup (your information will vary):
- ap-south-1a is pointing to ec2-13-126-190-48.ap-south-1.compute.amazonaws.com.
- ap-south-1b is pointing to ec2-13-126-202-244.ap-south-1.compute.amazonaws.com.
Note: You can only connect to one of the servers at a time, and that is the Primary Availability Zone server.
Testing Multi-AZ Failover
Referring to https://aws.amazon.com/rds/details/multi-az/, the Multi-AZ failover mode works in a synchronous Master/Slave relationship. There are two servers running simultaneously, the Primary one is accessible to end user, and the data is replicated in real time to a Secondary server (residing in a different zone), which is not accessible to the end user.
In case of a Primary Server’s unavailability, the Secondary Zone’s server is elevated to be the Primary, and hence accessible to the end user and application.
Test Case 1 – We’ll keep on connecting to the database and inserting one record every time in the database. The purpose is to check how much time does it take for the failover to happen. Basically Primary Availability Zone will become Secondary Availability Zone, and vice versa.
Test Case 2 – We’ll connect to the Primary Zone’s Instance directly (instead of using the Endpoint provided) and start adding the data through multiple clients. While the data is being added, we’ll reboot the machine with Failover mode on. It will make the Primary Zone secondary and inaccessible, and the Secondary Zone will now be made Primary. We will then verify the data insertion that we did on the now Secondary server, and if all records are available on the now Primary server.
I will use basic PHP scripting to test out the Failover capacity and if the data is replicated correctly. You can replicate it in any other language that you prefer.
- Install PHP & MySQL client
apt-get install mysql-client-core-5.6 php5-cli php5-mysql
- Connect to MySQL, and create a table in the MySQL Database (please replace the values based on your environment)
mysql -h testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com -u vivek -p FirstRDSdb
CREATE TABLE `failover_test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`cycle` varchar(50) DEFAULT NULL,
`counter` int(10) unsigned NOT NULL,
`failover_date` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 COMMENT='AWS RDS Failover Testing';
Test Case 1 Implementation
Create a PHP script named failover_test.php with the following content
<?php
$host = "testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com"; // AWS Endpoint
$user = "vivek";
$password = "password";
$dbname = "FirstRDSdb";
if (!isset($argv[1])) {
exit("Provide a cycle name\n");
}
if (!isset($argv[2])) {
exit("Provide the id value (that will be coming from for loop)\n");
}
$cycle = $argv[1];
$count = $argv[2];
$conn = mysqli_connect("$host","$user","$password","$dbname");
$q = mysqli_query($conn, "insert into failover_test set cycle='$cycle',counter='$count',failover_date=now() ");
if (!$q) {
$date = date("Y-m-d H:i:s");
echo "\n----------- NOT INSERTED $count / $date --------------\n";
} else {
echo "$count.";
}
mysqli_close($conn);
?>
Action Plan
- We will execute the above PHP script in a loop.
- While the terminal is executing the script, we will reboot the database with the option ‘Reboot with Failover?‘.
- We will monitor the PHP script and notice any numbers that are missing. The count of the missing numbers will give you the total downtime in seconds (approximately).
On your EC2 machine, from the same location where you saved your PHP script, run the following bash command from the terminal
for i in {1..5000}; do timeout 1 php failover_test.php cycle0 $i ; done
(You can use CTRL+C to terminate if you see any errors, or once your work/testing is over)
The above script does entry from 1 to 5000 (or increase it if the number is getting exhausted before you are able to do the testing) in the database. The “timeout” command is there to ensure that if there is no response for 1 second, the script will timeout & exit.
Now move on to the AWS console, and reboot the database instance with the option “Reboot With Failover?” selected.
Reboot with Failover option
Continue to monitor the script that is being executed.
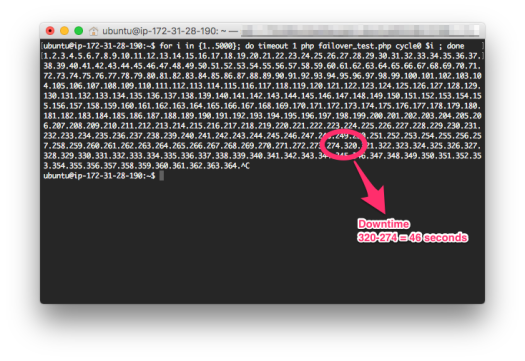
Calculating the Downtime. Use CTRL+C to end the script execution.
Note the duration where the data insertion pauses and no numbers are displayed. It means the Primary Zone’s server has shutdown, and your EC2 instance cannot connect to any RDS server. Once the numbers start showing up again after the delay, it refers to the server in the Secondary Zone now made primary. Note the total missing numbers; their count will tell you about the approximate seconds of total downtime that you faced.
Test Case 2
In this test, we will connect with only the Primary instance and flood it with data. We will then do a reboot and make the Secondary instance Primary. The aim is to test whether the data that was saved in Primary instance is correctly replicated to the Secondary.
Create a new PHP Script failover_load.php
<?php
// You need to get the relevant servers for your testing through
// monitoring DNS changes as I mentioned in the document above
$zoneA = "ec2-13-126-190-48.ap-south-1.compute.amazonaws.com.";
$zoneB = "ec2-13-126-202-244.ap-south-1.compute.amazonaws.com.";
// FOLLOWING IS VERY IMPORTANT
// Select the zone that is currently primary - so that your script can connect to it
// You can get this information from the AWS Console for your DB Instance
$host = $zoneB;
$user = "vivek";
$password = "password";
$dbname = "FirstRDSdb";
if (!isset($argv[1])) {
exit("Provide a cycle name\n");
}
$cycle = $argv[1];
$link = mysqli_init();
$conn = mysqli_connect("$host","$user","$password","$dbname");
for($count=1;$count<1000000;$count++) {
$q = mysqli_query($conn, "insert into failover_test set cycle='$cycle',counter='$count',failover_date=now()");
echo "$count.";
}
?>
Action Plan
- We will open 5 terminal windows and execute the above script 5 times, with different cycle names for differentiation
- While the scripts are being executed, we will reboot the Database instance with “Reboot with Failover?” option checked.
- Once the scripts stop adding further data, we’ll take the max numbers entered, and match it with the database records.
Open 5 terminal windows and connect to your EC2 instance, and prepare the execution of the failover_load.php script with different cycle names (just for identification).
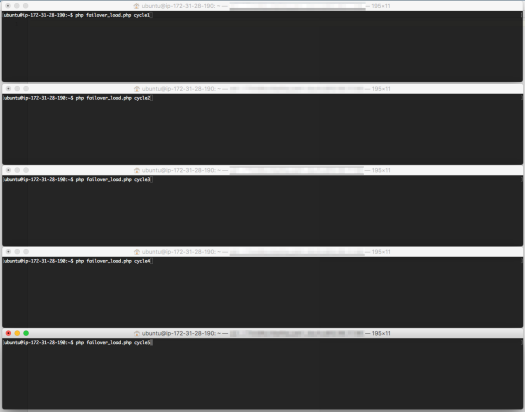
5 separate terminal windows, with different cycle names. Prepared for execution.
Now, execute one by one each of the commands. The faster you do, the better. While the data entry is being done, you can visit the AWS console, and reboot the DB instance with the option “Reboot with Failover?” option selected.
Reboot with Failover option
Why did we do this?
The purpose is to add data rapidly in the RDS database, and while the data is being written, we’ll reboot the database instance and make the ‘Secondary Zone’ the ‘Primary’. Since we connected directly to the RDS instance in the Primary Zone (ec2-13-126-202-244.ap-south-1.compute.amazonaws.com.) instead of using the default AWS provided endpoint (testrds.cdjw6bxi4s1f.ap-south-1.rds.amazonaws.com), as soon as the reboot is done, the server that we are inserting data in will stop responding.
You can see by referring to the screen below, the insertions stopped at the following numbers for each cycle
- cycle1 – 681
- cycle2 – 635
- cycle3 – 571
- cycle4 – 529
- cycle5 – 490
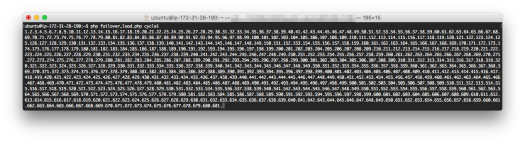
For Cycle1 – 681
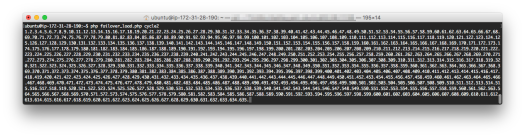
For Cycle2 – 635
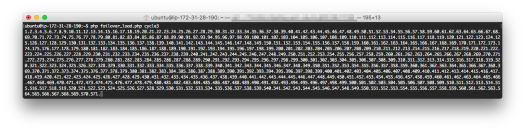
For Cycle3 – 571
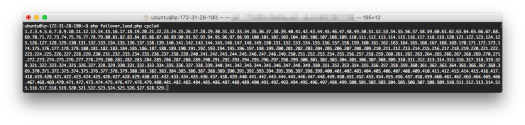
For Cycle4 – 529
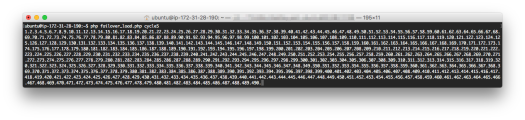
For Cycle5 – 490
We have already rebooted the database server, and now we have a new Primary Server.
We will connect to it using the mysql client from our EC2 machine, and run the following queries
ubuntu@ip-172-31-28-190:~$ mysql -h ec2-13-126-190-48.ap-south-1.compute.amazonaws.com. -u vivek FirstRDSdb -p
mysql>
mysql> select max(counter ) from failover_test where cycle='cycle1';
+---------------+
| max(counter ) |
+---------------+
| 681 |
+---------------+
1 row in set (0.01 sec)
mysql> select max(counter ) from failover_test where cycle='cycle2';
+---------------+
| max(counter ) |
+---------------+
| 635 |
+---------------+
1 row in set (0.01 sec)
mysql> select max(counter ) from failover_test where cycle='cycle3';
+---------------+
| max(counter ) |
+---------------+
| 571 |
+---------------+
1 row in set (0.01 sec)
mysql> select max(counter ) from failover_test where cycle='cycle4';
+---------------+
| max(counter ) |
+---------------+
| 529 |
+---------------+
1 row in set (0.01 sec)
mysql> select max(counter ) from failover_test where cycle='cycle5';
+---------------+
| max(counter ) |
+---------------+
| 490 |
+---------------+
1 row in set (0.01 sec)
If you notice, from the above, the relevant counter numbers match from what we saw while we were adding the data using the failover_load.php script.
What we can infer from the test results above is:
- MySQL does synchronous Primary/Slave replication
- If Primary Server goes down, the Secondary Server is made primary, and all the data available on Primary is replicated on Secondary and the services can continue to operate
- You can connect only to the Primary Server at a time
I believe the above is a fairly good implementation and we are able to simulate the failover setup. However, since the system is doing a clean reboot, the data is synchronised properly. A better test would have been to abruptly shutdown the database (due to hardware failure), and review how reliably and swiftly it did the failover.